神经网络的搭建——torch.nn
一、Container中的Moudule是所有的神经网络的基础、父类
-
所有的其他神经网络必须从Moudule中继承
-
自定义类中包括两个函数:初始化网络和前向传播
-
举一个简单的例子
import torch
from torch import nn
class ZBX(nn.Module):
def __init__(self):
super().__init__()
def forward(selfself, input):
output = input + 1
return output
zbx = ZBX()
x = torch.tensor(1.0)
output = zbx(x)
print(output)tensor(2.)二、torch.nn.functional()卷积相关操作
1.官方文档中介绍的conv2d()相关参数 链接
- Parameters
input – input tensor of shape
weight – filters of shape
bias – optional bias tensor of shape
. Default:
Nonestride – the stride of the convolving kernel. Can be a single number or a tuple (sH, sW). Default: 1
padding – implicit paddings on both sides of the input. Can be a single number or a tuple (padH, padW). Default: 0
dilation – the spacing between kernel elements. Can be a single number or a tuple (dH, dW). Default: 1
groups – split input into groups,
should be divisible by the number of groups. Default: 1
import torch
import torch.nn.functional as F例如,如果我们想要对下面的矩阵用3*3的卷积核做卷积操作
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])打印出他们的形状
print(input.shape)
print(kernel.shape)torch.Size([5, 5])
torch.Size([3, 3])这与官方文档中要求的不符合,所以要进行变换
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])这样便得到了我们想要的尺寸
下面对5*5的图像做卷积操作
下面分别以步距为1和2时的卷积操作为例
output1 = F.conv2d(input, kernel, stride=1)
print(output1)tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])output2 = F.conv2d(input, kernel, stride=2)
print(output2)tensor([[[[10, 12],
[13, 3]]]])为填充操作,默认为零,下面举例说明
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])三、神经网络中的卷积层
1.二位卷积层 Conv2d
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1,padding=0)
def forward(self, x):
x = self.conv1(x)
return x
zbx = ZBX()
print(zbx)Files already downloaded and verified
ZBX(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)上面的代码演示了如何建立一个只有一个二维卷积层的神经网络
for data in dataloader:
imgs, targets = data
output = zbx(imgs)
print(imgs.shape)
print(output.shape)torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
torch.Size([64, 3, 32, 32])
......64为batch_size,6为out_channels,30*30为卷积后所得图片的大小
下面将结果保存到summarywriter中
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1,padding=0)
def forward(self, x):
x = self.conv1(x)
return x
zbx = ZBX()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs, targets = data
output = zbx(imgs)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
writer.close()Files already downloaded and verified运行后便可以在teosorboard中看到卷积后的结果
2.最大池化层 MaxPool2d
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
zbx=ZBX()
output = zbx(input)
print(output)tensor([[[[2., 3.],
[5., 1.]]]])ceil_mode决定是否要对多余的部分做池化操作,注意如果有下面这样的报错
RuntimeError: "max_pool2d" not implemented for 'Long'则需要在input的后面加上
dtype=torch.float32这句话
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
zbx=ZBX()
output = zbx(input)
print(output)tensor([[[[2.]]]])将ceil_mode改为false后,便舍去了后面的部分
- 最大池化的作用:减少数据量,提高效率
直观感受
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
zbx=ZBX()
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output=zbx(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()Files already downloaded and verified运行完后便可以在tendorboard中看到效果,做了最大池化操作后图像变模糊了
3.非线性激活层 链接
- 神经网络中最常用的非线性激活函数为RELU和sigmoid函数
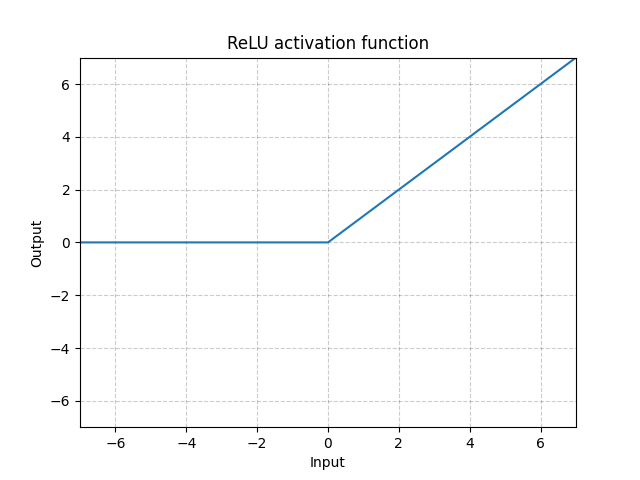 RELU激活函数
RELU激活函数
ReLU中的参数inplace参数解释
input = -1
ReLU(input, inplace=True)将inplace设为True,那么运行此行代码以后input的值会变为1
input = -1
output = ReLU(input, inplace=False)将inplace设为Flase,那么运行此行代码以后input的值会不变,依然为-1,output变为0
- 具体用法如下:
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
output = torch.reshape(input, (-1,1,2,2,))
print(output.shape)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.relu1 = ReLU(inplace=False)
def forward(self, input):
output = self.relu1(input)
return output
zbx = ZBX()
output = zbx(input)
print(output)torch.Size([1, 1, 2, 2])
tensor([[1., 0.],
[0., 3.]])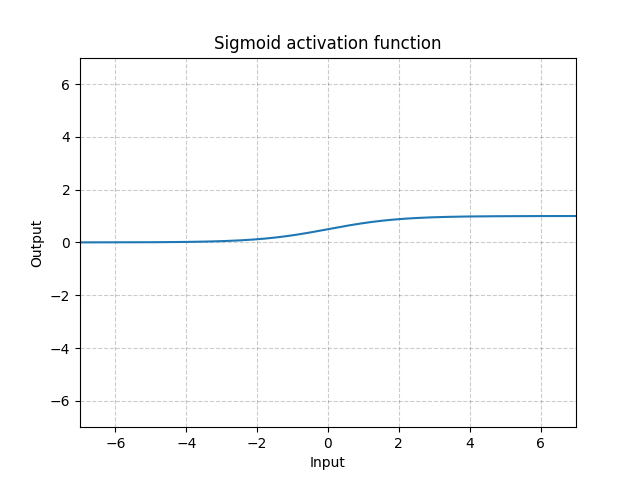 Sigmoid激活函数
Sigmoid激活函数
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
zbx = ZBX()
writer = SummaryWriter("log_relu")
step = 0
for data in dataloader:
imgs, target = data
writer.add_images("input", imgs, global_step=step)
output = zbx(imgs)
writer.add_images("output", output, global_step=step)
step = step + 1
writer.close()Files already downloaded and verified运行代码后,便可以在tensorboard中看到经过非线性激活后的图像
4.线性层 Linear
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset,batch_size=64)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
zbx = ZBX()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.reshape(imgs,(1,1,1,-1))
print(output.shape)
output = zbx(output)
print(output.shape)Files already downloaded and verified
torch.Size([64, 3, 32, 32])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([64, 3, 32, 32])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([64, 3, 32, 32])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([64, 3, 32, 32])
torch.Size([1, 1, 1, 196608])
......
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_24716\2187972730.py in <module>
27 output = torch.reshape(imgs,(1,1,1,-1))
28 print(output.shape)
---> 29 output = zbx(output)
30 print(output.shape)
D:\anaconda\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
~\AppData\Local\Temp\ipykernel_24716\2187972730.py in forward(self, input)
17
18 def forward(self, input):
---> 19 output = self.linear1(input)
20 return output
21
D:\anaconda\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
D:\anaconda\anaconda3\lib\site-packages\torch\nn\modules\linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x49152 and 196608x10)- 除了reshape以外,也可以直接使用flatten
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset,batch_size=64)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
zbx = ZBX()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = zbx(output)
print(output.shape)Files already downloaded and verified
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
......
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_24716\671123244.py in <module>
27 output = torch.flatten(imgs)
28 print(output.shape)
---> 29 output = zbx(output)
30 print(output.shape)
D:\anaconda\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
~\AppData\Local\Temp\ipykernel_24716\671123244.py in forward(self, input)
17
18 def forward(self, input):
---> 19 output = self.linear1(input)
20 return output
21
D:\anaconda\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
D:\anaconda\anaconda3\lib\site-packages\torch\nn\modules\linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x49152 and 196608x10)四、神经网络搭建实战
1.CIFAR10神经网络实战
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
zbx=ZBX()
print(zbx)ZBX(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)- 如何知道自己的网络模型是否正确?
input = torch.ones(64, 3, 32, 32)
output = zbx(input)print(output)tensor([[ 0.0981, 0.0425, 0.1179, 0.1857, 0.0187, 0.0927, -0.0108, 0.1502,
0.0592, 0.0832],
[ 0.0981, 0.0425, 0.1179, 0.1857, 0.0187, 0.0927, -0.0108, 0.1502,
0.0592, 0.0832],
[ 0.0981, 0.0425, 0.1179, 0.1857, 0.0187, 0.0927, -0.0108, 0.1502,
0.0592, 0.0832],
[ 0.0981, 0.0425, 0.1179, 0.1857, 0.0187, 0.0927, -0.0108, 0.1502,
0.0592, 0.0832],
[ 0.0981, 0.0425, 0.1179, 0.1857, 0.0187, 0.0927, -0.0108, 0.1502,
0.0592, 0.0832],
......
[ 0.0981, 0.0425, 0.1179, 0.1857, 0.0187, 0.0927, -0.0108, 0.1502,
0.0592, 0.0832]], grad_fn=<AddmmBackward0>)print(output.shape)torch.Size([64, 10])根据输出尺寸可得知,模型参数设置基本正确
from torch.utils.tensorboard import SummaryWriter
zbx=ZBX()
input = torch.ones((64, 3, 32, 32))
writer = SummaryWriter("logs_seq")
writer.add_graph(zbx, input)
writer.close()运行以后,便可以在tensorboard中看到自己所创建的神经网络了
五、损失函数的计算
损失函数的作用
-
计算实际输出和目标之间的差距
-
为我们更新输出提供一定的依据(反向传播)
1.L1Loss()损失函数 链接
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets)
print(result)tensor(0.6667)可以将L1Loss中的默认值设为sum,这样得到的就是总和而不是平均值
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
print(result)tensor(2.)2.平方差损失函数 MSELOSS
from torch import nn
loss_mse = nn.MSELoss()
result = loss_mse(inputs, targets)
print(result)tensor(1.3333)3.交叉熵损失函数 CrossEntropyLoss
假设有一张狗的图片和一个神经网络,三个预测类别分别为(0, 1, 2)
经过神经网络输出后,输出的值为
狗这个类别所在的下标为1,
那么损失的计算方式为
根据计算可得结果为1.10194284823
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result = loss_cross(x,y)
print(result)tensor(1.1019)损失函数应用于神经网络
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset ,batch_size=1)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
zbx = ZBX()
for data in dataloader:
imgs, targets = data
outputs = zbx(imgs)
print(outputs)
print(targets)Files already downloaded and verified
tensor([[-0.0040, 0.1075, -0.0019, -0.0165, -0.0177, -0.0568, -0.0950, 0.1084,
-0.0797, -0.0431]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor([[ 0.0080, 0.0937, -0.0214, -0.0081, -0.0265, -0.0708, -0.0906, 0.1453,
-0.0819, -0.0342]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[-0.0023, 0.1161, 0.0022, -0.0245, -0.0389, -0.0717, -0.0861, 0.1339,
-0.0827, -0.0478]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor([[ 0.0094, 0.1208, -0.0210, -0.0242, -0.0235, -0.0717, -0.0987, 0.1249,
-0.0781, -0.0374]], grad_fn=<AddmmBackward0>)
tensor([5])
tensor([[ 0.0053, 0.1146, -0.0050, -0.0203, -0.0276, -0.0678, -0.0847, 0.1171,
-0.0676, -0.0319]], grad_fn=<AddmmBackward0>)
tensor([1])
tensor([[-0.0123, 0.1074, -0.0020, -0.0338, -0.0279, -0.0664, -0.0737, 0.1161,
-0.0829, -0.0403]], grad_fn=<AddmmBackward0>)
tensor([7])import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset ,batch_size=1)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()
zbx = ZBX()
for data in dataloader:
imgs, targets = data
outputs = zbx(imgs)
result_loss = loss(outputs, targets)
print(result_loss)Files already downloaded and verified
tensor(2.2424, grad_fn=<NllLossBackward0>)
tensor(2.3161, grad_fn=<NllLossBackward0>)
tensor(2.3182, grad_fn=<NllLossBackward0>)
tensor(2.4337, grad_fn=<NllLossBackward0>)
......
tensor(2.3386, grad_fn=<NllLossBackward0>)
tensor(2.3874, grad_fn=<NllLossBackward0>)- 利用损失函数和梯度下降,可以对神经网络进行反向传播来优化整个神经网络,如下是反向传播的代码
for data in dataloader:
imgs, targets = data
outputs = zbx(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()六、优化器 optimizer
-
学习速率lr参数是所有优化器中必有的参数
-
添加完学习速率以后,运行代码便可以得到一轮训练的结果
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset ,batch_size=1)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()
zbx = ZBX()
optim = torch.optim.SGD(zbx.parameters(), lr=0.01)
for data in dataloader:
imgs, targets = data
outputs = zbx(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
print(result_loss)Files already downloaded and verified
tensor(2.3056, grad_fn=<NllLossBackward0>)
tensor(2.4387, grad_fn=<NllLossBackward0>)
tensor(2.3366, grad_fn=<NllLossBackward0>)
......
tensor(0.8155, grad_fn=<NllLossBackward0>)
tensor(2.4733, grad_fn=<NllLossBackward0>)
tensor(0.7009, grad_fn=<NllLossBackward0>)- 为了使模型更好,在外面再套一层循环,表示训练模型的次数
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset ,batch_size=1)
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, kernel_size=5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()
zbx = ZBX()
optim = torch.optim.SGD(zbx.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = zbx(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print(running_loss)
七、现有网络模型的使用及修改
- 以vggl6为例
import torchvision
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)D:\anaconda\anaconda3\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
warnings.warn(
D:\anaconda\anaconda3\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
D:\anaconda\anaconda3\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)vgg16设置为false的情况下,模型参数都是未经过训练的,设置为True时,模型参数都是已经训练好的
print(vgg16_true)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)vgg_16是在ImageNet上训练好的
由于ImageNet有1000个类别,故ImageNet有1000个输出通道,而我们要预测的CIFAR10有10个类别, 为了使官方训练好的vgg_16能够应用于CIFAR10数据集,可以使用下面的方式来对官方的模型做修改
import torchvision
from torch import nn
from torch.nn import Linear
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_true.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)D:\anaconda\anaconda3\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
warnings.warn(
D:\anaconda\anaconda3\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
D:\anaconda\anaconda3\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Files already downloaded and verified
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)同样,也可以通过类似的方式加到classifier里面
import torchvision
from torch import nn
from torch.nn import Linear
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Files already downloaded and verified
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
)同样,也可以直接修改最后一层的输出参数,使之从1000变为10
print(vgg16_false)
vgg16_false.classifier[6] = Linear(4096,10)
print(vgg16_false)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)八、模型的保存和加载
保存方式一
1.模型的保存
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16, "vgg16_method1.pth")运行完以后不仅保存了网络模型的结构,也保存了网络模型中的一些参数
2.模型的加载
import torch
model = torch.load("vgg16_method1.pth")
print(model)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)保存方式二
1.模型的保存
torch.save(vgg16.state_dict(), "vgg16_method2.pth")这种保存方式保存的是模型的参数,存储所需要的空间更小
2、模型的加载
model = torch.load("vgg16_method2.pth")
print(model)OrderedDict([('features.0.weight', tensor([[[[ 0.1877, 0.0119, -0.0333],
[ 0.0580, -0.0016, 0.1273],
[-0.0105, -0.0329, -0.0166]],
[[ 0.0387, 0.0086, 0.0480],
[-0.1841, -0.0060, -0.0965],
[-0.0397, 0.0320, -0.1531]],
[[-0.0834, 0.0986, -0.0322],
[ 0.0248, 0.0200, 0.0241],
[-0.0103, 0.0696, 0.0187]]],
[[[ 0.0063, -0.0240, -0.0048],
[-0.0117, -0.0535, 0.0899],
[ 0.0414, -0.0082, -0.0307]],
[[ 0.0370, 0.0077, -0.1648],
[-0.1122, 0.0842, -0.0699],
[-0.0690, -0.0803, 0.0083]],
[[ 0.0075, 0.0082, 0.0776],
[-0.1263, -0.0741, 0.0449],
[-0.0031, 0.0148, -0.0063]]],
[[[ 0.0505, -0.0098, 0.0274],
[-0.0240, 0.0704, 0.0076],
[-0.0940, -0.0753, -0.0353]],
[[ 0.0331, 0.0086, -0.0242],
[-0.0398, 0.0900, -0.0134],
[-0.0126, -0.0239, 0.0857]],
[[ 0.0360, -0.0255, -0.0739],
[-0.1158, 0.0631, -0.1346],
[ 0.0077, 0.0199, 0.0267]]],
…,
[[[ 0.0929, -0.1198, -0.0047],
[ 0.0255, 0.0615, 0.0335],
[-0.0677, -0.0944, 0.0266]],
[[ 0.0083, -0.1262, -0.1517],
[-0.0766, -0.0661, -0.0388],
[-0.0197, 0.1495, 0.0728]],
[[-0.0068, -0.0297, -0.0870],
[-0.0281, -0.1187, 0.0225],
[ 0.1221, 0.0089, 0.0760]]],
[[[-0.1003, 0.0413, 0.0310],
[-0.0326, -0.0224, -0.0193],
[ 0.0367, 0.0687, -0.0537]],
[[ 0.0867, 0.0352, -0.1267],
[-0.0205, -0.0131, 0.0244],
[-0.1558, 0.0959, -0.0532]],
[[-0.0210, -0.0081, 0.0709],
[-0.0388, -0.0395, -0.0771],
[ 0.0131, -0.0064, 0.0590]]],
[[[ 0.0544, -0.1418, 0.0541],
[-0.0253, -0.0451, -0.0481],
[ 0.0318, -0.0046, -0.1456]],
[[ 0.0195, -0.0570, 0.0370],
[ 0.0457, -0.1030, -0.0525],
[ 0.1012, 0.0425, -0.0072]],
[[-0.0219, 0.0210, -0.0018],
[-0.0072, -0.0321, -0.0576],
[-0.0819, 0.0050, -0.1687]]]])), ('features.0.bias', tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])), ('features.2.weight', tensor([[[[-0.0163, -0.1110, -0.0549],
[ 0.0398, -0.0607, -0.0017],
[-0.0735, 0.1155, 0.0191]],
[[ 0.0727, 0.0663, -0.0275],
[ 0.0912, -0.0292, -0.0357],
[-0.0220, -0.0053, 0.0536]],
[[ 0.0277, -0.0231, -0.0767],
[ 0.0454, -0.1098, -0.0247],
[-0.0409, -0.1778, -0.1217]],
...,
[[[-1.0162e-02, -4.3320e-02, -1.1225e-02],
[ 2.1126e-02, 2.2012e-02, 2.1988e-03],
[ 2.0674e-03, -7.9697e-04, -2.4580e-02]],
[[ 2.0350e-02, 1.1330e-02, 3.6683e-03],
[ 2.9473e-03, -8.0246e-03, -1.7149e-02],
[-7.3402e-03, 4.2107e-02, 4.0811e-03]],
[[-3.8155e-02, -7.7102e-03, -1.2026e-02],
[ 2.6956e-03, -3.0665e-02, 5.6342e-04],
[-4.7007e-03, 1.4807e-02, 1.3091e-03]],
...,
[[-1.9435e-02, 1.8673e-02, 2.1690e-02],
[-7.3898e-04, 2.1838e-03, -6.7337e-03],
[-3.4759e-02, -1.0963e-02, 2.7159e-02]],
[[-1.8573e-02, 7.2324e-03, -1.2427e-02],
[ 1.9773e-03, 2.7289e-02, 2.3881e-02],
[-1.1245e-02, -3.1190e-02, -1.8227e-02]],
[[-1.4401e-02, -6.9929e-03, -1.7822e-02],
[ 1.6773e-03, 5.2941e-03, 4.2670e-02],
[-3.6425e-04, -4.2002e-02, -2.2823e-02]]],
[[[-1.1492e-03, 1.5467e-02, 1.0771e-02],
[-5.0946e-04, -9.1521e-03, 9.3125e-03],
[-4.0188e-03, -1.3066e-02, -4.6290e-03]],
[[ 7.8103e-03, -1.0956e-02, -2.4251e-03],
[ 2.0508e-03, 2.6945e-03, 1.4582e-02],
[ 2.9491e-02, 1.2938e-02, -2.1569e-02]],
[[-2.7496e-03, 3.2970e-03, -1.9424e-02],
[-1.4180e-02, 1.9399e-02, 2.1333e-02],
[-2.0066e-02, -9.8992e-03, 3.1895e-03]],
...,
[[ 2.9996e-02, -1.7047e-02, 4.4760e-02],
[ 2.1302e-02, -4.2940e-03, -2.9054e-02],
[ 2.8626e-03, -1.0866e-02, 4.9905e-03]],
[[ 2.3969e-02, -1.4120e-02, -4.7572e-03],
[ 1.4596e-02, 3.4929e-02, 1.0635e-02],
[ 1.6932e-02, 1.5369e-02, -1.1296e-02]],
[[-1.6734e-02, -5.5271e-03, -1.8718e-02],
[-2.0536e-02, 2.0149e-03, 2.7606e-02],
[-1.4193e-02, -2.5598e-02, -2.5878e-02]]]])), ('features.28.bias', tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0.])), ('classifier.0.weight', tensor([[-0.0196, -0.0063, 0.0100, ..., 0.0020, -0.0205, 0.0014],
[-0.0087, 0.0035, -0.0004, ..., -0.0020, 0.0051, 0.0076],
[-0.0036, 0.0073, -0.0010, ..., 0.0033, -0.0085, 0.0017],
...,
[ 0.0062, -0.0025, 0.0098, ..., 0.0069, -0.0022, 0.0122],
[ 0.0096, -0.0033, -0.0021, ..., -0.0018, 0.0130, -0.0017],
[-0.0122, -0.0019, 0.0127, ..., 0.0235, 0.0072, 0.0029]])), ('classifier.0.bias', tensor([0., 0., 0., ..., 0., 0., 0.])), ('classifier.3.weight', tensor([[-0.0181, -0.0105, -0.0071, ..., 0.0136, -0.0008, 0.0122],
[-0.0126, -0.0112, -0.0185, ..., 0.0154, 0.0048, -0.0048],
[-0.0021, -0.0039, -0.0036, ..., -0.0022, -0.0001, 0.0015],
...,
[-0.0083, 0.0151, 0.0055, ..., -0.0103, 0.0138, -0.0245],
[-0.0092, 0.0056, 0.0004, ..., 0.0010, 0.0049, -0.0049],
[ 0.0142, -0.0029, -0.0272, ..., 0.0044, -0.0119, -0.0049]])), ('classifier.3.bias', tensor([0., 0., 0., ..., 0., 0., 0.])), ('classifier.6.weight', tensor([[ 3.8369e-03, 8.8565e-04, -7.2871e-03, ..., 8.0417e-03,
2.1974e-03, 1.8603e-03],
[-1.0361e-03, -3.2669e-04, -9.9105e-05, ..., -1.5281e-03,
-8.3753e-03, 3.6039e-03],
[ 7.0149e-03, 1.1348e-02, -1.3105e-02, ..., -1.2069e-02,
5.3160e-03, 1.5984e-02],
...,
[-1.7612e-03, 1.2150e-05, -1.5098e-02, ..., -4.7140e-03,
7.6691e-03, 1.8036e-02],
[ 6.0087e-03, 9.6107e-03, -1.3611e-03, ..., -7.4399e-04,
1.3930e-02, -1.2126e-02],
[-5.1181e-04, -2.7398e-03, -1.9116e-02, ..., 1.1337e-02,
-1.2211e-02, 1.0711e-02]])), ('classifier.6.bias', tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))])可以看出,第一种保存方式保存的是网络模型的架构及参数,第二种保存方式仅保存了参数
- 加载网络模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)这样便可以把模型参数转化为模型架构了
第一种保存方式虽然更加简便,但是有陷阱,下面举例说明
比如,我们通过第一种方式保存了一个网络模型
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
vgg16 = torchvision.models.vgg16(pretrained=False)
# torch.save(vgg16, "vgg16_method1.pth")
torch.save(vgg16.state_dict(), "vgg16.method2.pth")
class ZBX(nn.Module):
def __init__(self):
super(ZBX, self).__init__()
self.conc1 = Conv2d(3, 64,kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
zbx = ZBX()
torch.save(zbx, "zbx_method1.pth")陷阱
model = torch.load("zbx_method1.pth")
print(model)ZBX(
(conc1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1))
)在Pycharm中运行便会产生这样的报错(不要管这一行命令在jupyter notebook中正常运行)
AttributeError: Can't get attribute 'ZBX' on <module '__main__' from 'D:\\Micro_Climate_Summer_Task\\Pytorch_For_Deep_Learning\\model_load.py'>